Distributed Wisdom: Running a Thinking Network on $200 Hardware
📚 More on this topic: Why mycoSwarm Was Born · CPU-Only LLMs · Budget AI PC Under $500 · Local RAG Guide
What if your AI didn’t run on one machine — it thought across several?
Not in the cloud. Not through an API. On a cluster of used office PCs you bought for $30 each, coordinated by a framework that distributes intelligence the way mycelium distributes nutrients through a forest.
That’s mycoSwarm. It turns cheap hardware into a cooperative thinking network. One node has the GPU for heavy inference. Others handle intent classification, web search, and retrieval — each contributing what it can. The whole system runs locally, privately, with no data leaving your network.
The Hardware

| Node | Hardware | Role | Cost |
|---|---|---|---|
| Miu | i7-8086K + RTX 3090, 64GB | Executive — runs gemma3:27b for inference | Already owned |
| naru | Lenovo M710Q, i7-6700T, 8GB | Light — intent classification, web search | ~$30 |
| boa | Lenovo M710Q (planned) | Light — intent classification, web search | ~$30 |
| Pi | Raspberry Pi | Discovery + monitoring | Already owned |
Total additional cost: under $100. The M710Qs are ex-corporate machines that show up on eBay constantly. They’re small, silent, and draw about 35 watts each.
The framework classifies nodes into tiers automatically based on detected hardware:
class NodeTier(str, Enum):
EDGE = "edge" # Minimal: RPi, Arduino, phone
LIGHT = "light" # CPU-only: ThinkCentre, old laptop
WORKER = "worker" # Entry GPU or strong CPU
SPECIALIST = "specialist" # Mid-high GPU: 3060, 3070, 4060
EXECUTIVE = "executive" # High-ultra GPU: 3090, 4090, A6000
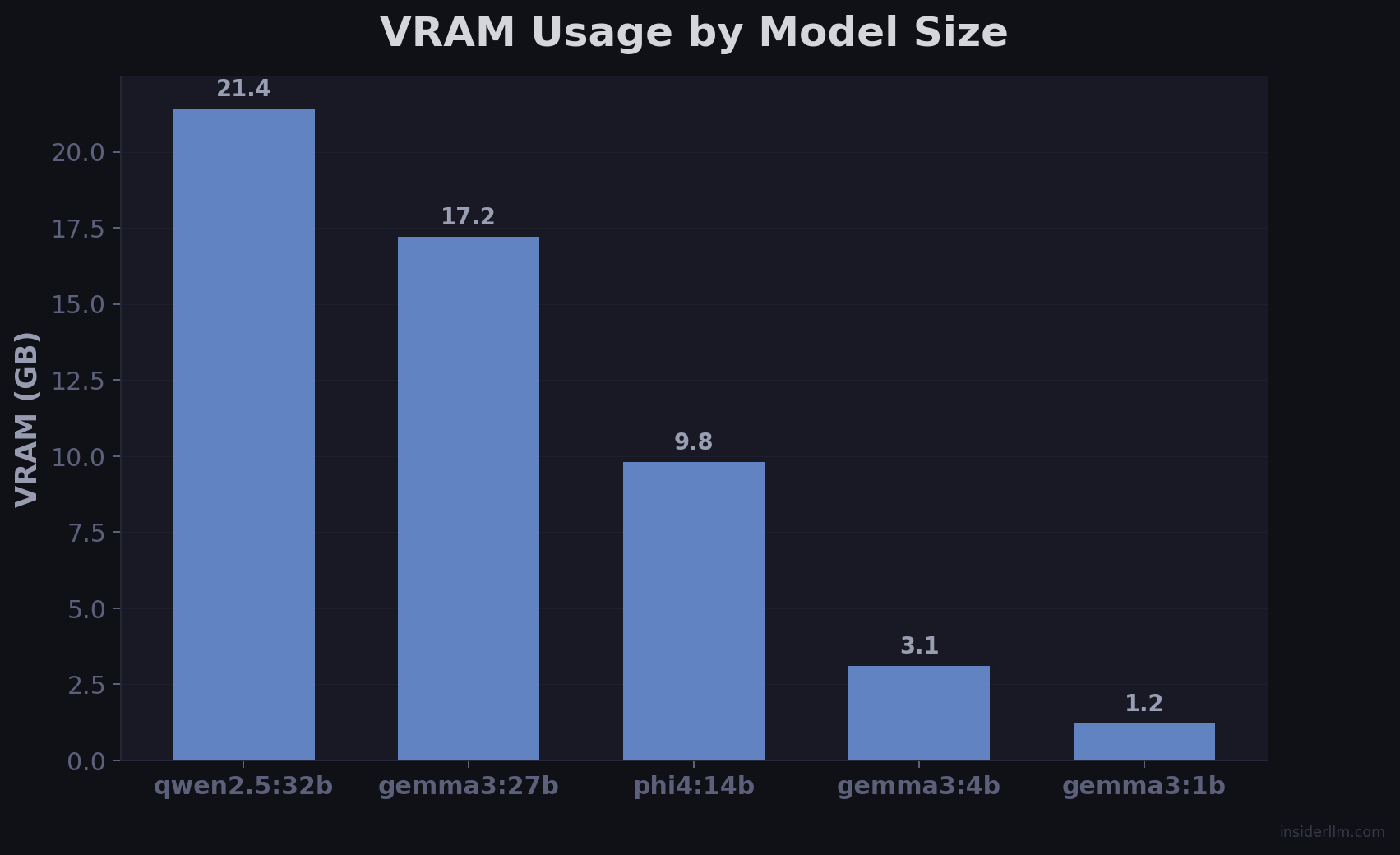
A 3090 is classified as executive. The M710Qs are light. The Pi is edge. The orchestrator routes tasks based on these tiers — heavy inference to executive nodes, gate tasks to light nodes, monitoring to edge.
Why Distribute?
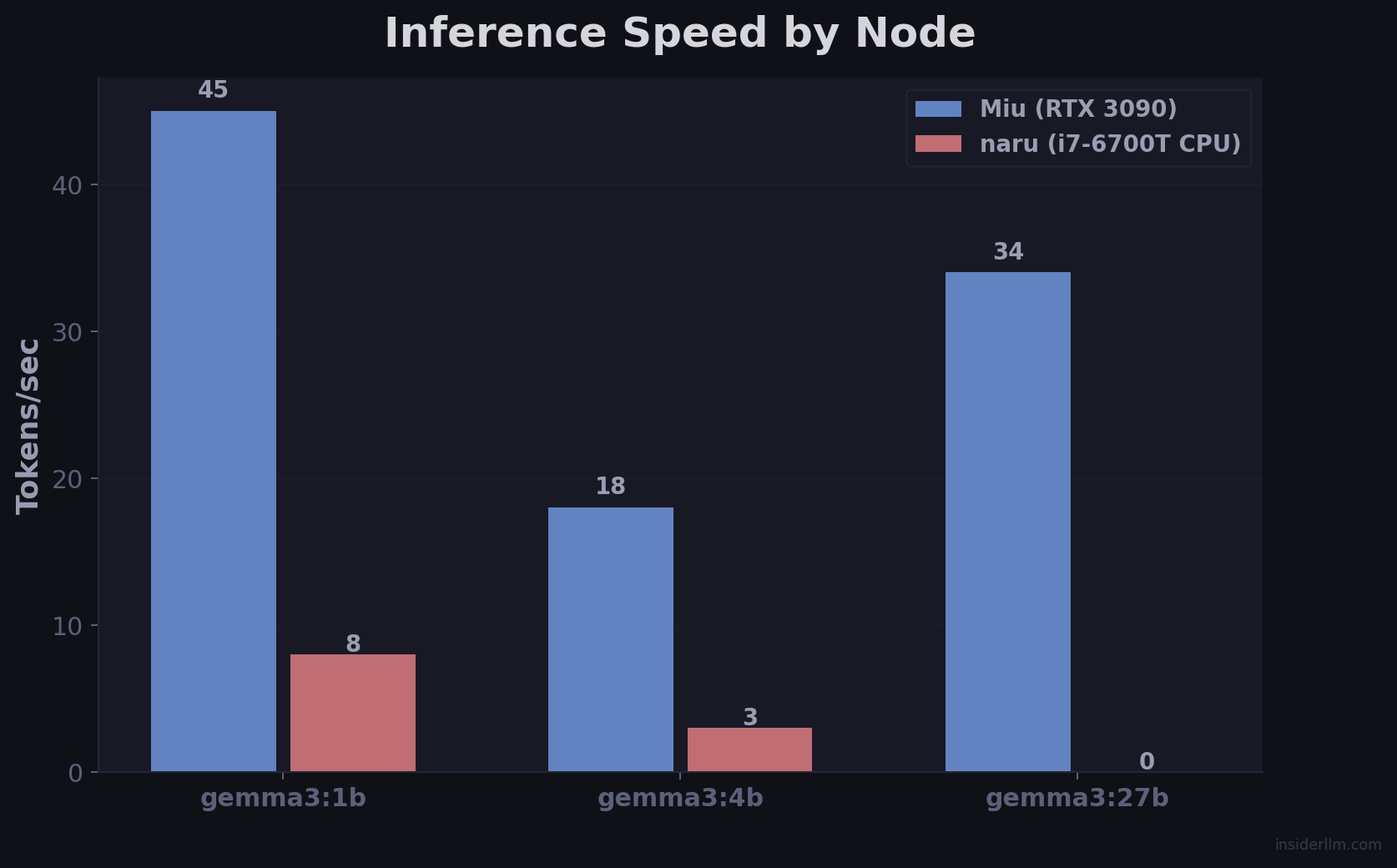
A single machine with a 3090 can run a 27B model at ~34 tokens/second. That’s good. But while it’s generating tokens, everything else stalls. Intent classification, web search, document retrieval, session summarization — they all compete for the same GPU.
Distribution separates thinking from doing:
- Intent classification runs on a 1B model. Any CPU handles it. Ship it to the nearest idle M710Q.
- Web search is I/O-bound, not compute-bound. Perfect for CPU workers.
- Document embedding uses nomic-embed-text. Runs fine on CPU.
- Heavy inference — the actual conversation — stays on the GPU node.
The result: while the 3090 generates your response at 34 tok/s, three M710Qs simultaneously classify your next query’s intent, run web searches, and pre-fetch documents. The pipeline never stalls.
Zero-Config Discovery
Nodes find each other automatically via mDNS (multicast DNS) — the same protocol your printer uses. Start the daemon on any machine on your local network:
pip install mycoswarm
mycoswarm daemon
Within seconds, it discovers every other mycoSwarm node. No configuration files. No IP addresses to type. No coordinator to set up. Each node broadcasts its capabilities (GPU tier, available models, CPU cores) and the orchestrator routes tasks to the best available node.
$ mycoswarm swarm
🍄 mycoSwarm Cluster
4 nodes online
Miu RTX 3090 24GB gemma3:27b, gemma3:1b executive
naru M710Q i7-6700T gemma3:1b light
boa M710Q i7-6700T gemma3:1b light
pi Raspberry Pi — edge
The Query Pipeline
Every user message flows through a structured pipeline before generating a response:
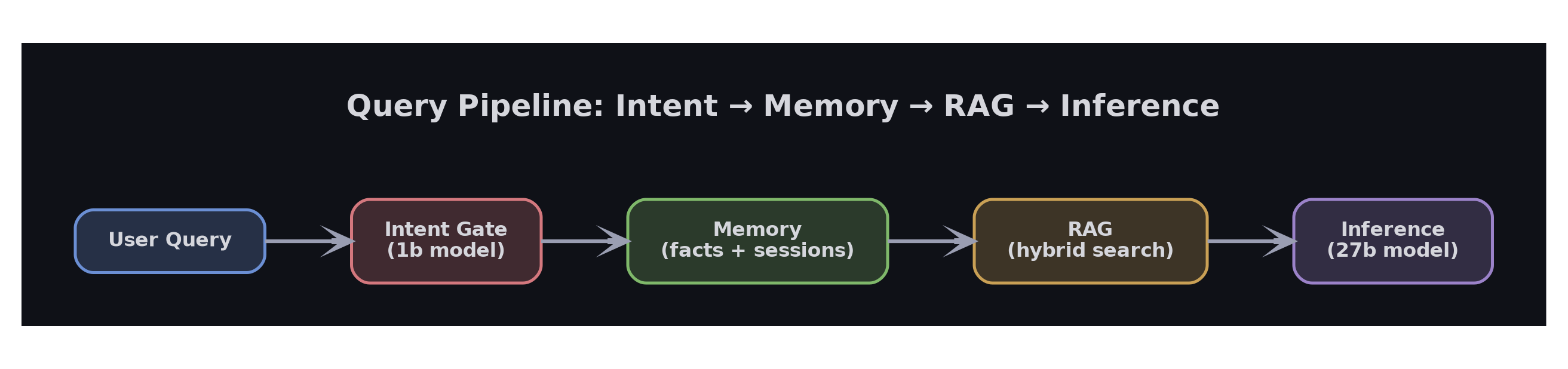
Step 1: Intent Classification Gate
A small 1B model (running on whichever CPU worker is least busy) classifies the query before anything else happens:
def _pick_gate_model() -> str | None:
"""Pick the smallest available model for gate tasks."""
for pattern in ("gemma3:1b", "llama3.2:1b", "gemma3:4b", "llama3.2:3b"):
for m in models:
if pattern in m and not _is_embedding_model(m):
return m
# Fall back to first non-embedding model
for m in models:
if not _is_embedding_model(m):
return m
return None
The gate returns a structured three-field intent:
def intent_classify(query: str, model: str | None = None) -> dict:
"""Classify user intent with structured output.
Returns: {
"tool": "answer" | "web_search" | "rag" | "web_and_rag",
"mode": "recall" | "explore" | "execute" | "chat",
"scope": "session" | "docs" | "facts" | "all"
}
"""
# ... calls the gate model, parses JSON response ...
# Override: docs scope never needs web search
if result["scope"] == "docs" and result["tool"] == "web_and_rag":
result["tool"] = "rag"
return result
This three-field schema tells the system: use document retrieval (not web search), in recall mode (looking for something specific), scoped to the document library (not session history). The gate model runs on a M710Q in about 200ms. The GPU never sees it.
Step 2: Memory Retrieval
The system loads the user’s persistent memory — facts they’ve told it to remember, plus semantically relevant past conversations:
parts = [
"You are a local AI assistant with persistent memory and a "
"document library. When document excerpts [D1], [D2] etc. or "
"session memories [S1], [S2] etc. appear in your context, "
"these are REAL retrieved results...",
"Your memory has two distinct sources:\n"
" 1. FACTS — things the user explicitly told you to remember\n"
" 2. SESSION HISTORY — summaries of past conversations with dates.",
]
Facts are things like “I use a 3090” or “I keep bees.” Session history is structured reflections on past conversations, ranked by semantic relevance to the current query.
Step 3: Hybrid RAG Search
If the intent says rag or web_and_rag, the system runs a hybrid search combining vector similarity with BM25 keyword matching, fused via Reciprocal Rank Fusion:
def search_all(
query: str, n_results: int = 5, intent: dict | None = None, ...
) -> tuple[list[dict], list[dict]]:
"""Search BOTH document library and session memory.
Uses vector similarity (ChromaDB) + BM25 keyword matching,
merged via Reciprocal Rank Fusion (RRF).
Returns (doc_hits, session_hits).
"""
# ... embed query, search both collections ...
# Source priority: boost user documents 2x
# Contradiction detection: drop conflicting sessions
# Poison loop detection: quarantine repeated hallucinations
Old sessions naturally fade in priority through recency decay:
def _recency_decay(date_str: str, half_life_days: int = 30) -> float:
"""Exponential decay with 30-day half-life.
Today's session = 1.0. A month ago = ~0.5. Never below 0.1.
"""
age_days = (datetime.now() - session_date).days
if age_days <= 0:
return 1.0
decay = math.pow(0.5, age_days / half_life_days)
return max(0.1, round(decay, 4))
Step 4: Inference
The actual response generates on the GPU node (the 3090), with the full context assembled: user query, memory, retrieved documents, and session history. The model sees everything as one coherent prompt, not scattered system messages.
Four Memory Types

Inspired by cognitive science (the CoALA framework from Princeton), mycoSwarm implements four distinct memory systems:
Working Memory — the current conversation context. Limited by the model’s context window. This is what every chatbot has.
Semantic Memory — your document library. PDFs, markdown files, code — chunked, embedded, and indexed in ChromaDB. Hybrid retrieval combines vector similarity with BM25 keyword matching.
Episodic Memory — structured records of past conversations. Not just “we discussed X” but what decisions were made, what was learned, what was surprising, and the emotional tone. Lessons are indexed separately for future retrieval.
Procedural Memory — rules, skills, and patterns. Currently stored as system prompt instructions and user-defined facts. Growing toward an exemplar store of “how we solved X before.”
Self-Correcting Memory
The most novel piece. Every session summary passes through a grounding check before being indexed. Low-quality summaries are blocked. When session memories contradict actual documents, the documents win. When the same ungrounded claim appears across multiple sessions, the system recognizes a poison loop and quarantines the affected memories.
Rich Episodic Reflection
When you end a chat session, mycoSwarm doesn’t just summarize — it reflects:
Reflecting on session... done. (grounding: 75%)
Tone: discovery
Lesson: Taoist philosophy prioritizes individual spiritual development
over collective social reform.
Lesson: The root of societal problems lies within individuals, and
therefore solutions must also be internal.
These lessons get indexed into ChromaDB as searchable knowledge. In future sessions, when a related topic comes up, the system retrieves not just “we discussed Taoism” but the specific insight that was discovered.
Real Performance
On the cluster:
| Task | Node | Time |
|---|---|---|
| Intent classification | Any M710Q | ~200ms |
| Web search (3 queries parallel) | 3 M710Qs simultaneously | ~1.5s total |
| Document retrieval (hybrid) | Miu | ~300ms |
| Full response (gemma3:27b) | Miu (3090) | 3-10s at ~34 tok/s |
| Session reflection | Miu | ~3s |
Parallel web search is where distribution shines hardest. Instead of three searches sequentially (4.5s), they fan out across three CPU workers and complete in the time of one (1.5s).
The Stack
Everything runs on Ollama for model serving, ChromaDB for vector storage, and FastAPI for the inter-node API:
- ollama — local model serving
- chromadb — vector database
- fastapi + uvicorn — node API
- zeroconf — mDNS discovery
- httpx — HTTP client
- ddgs — DuckDuckGo search (no API key)
No cloud dependencies. No API keys (except optionally for web search). No telemetry. Your conversations, documents, and memories stay on your hardware.
Build Your Own
Start with one machine:
pip install mycoswarm
mycoswarm chat
This gives you single-node mode — direct Ollama inference with memory, RAG, and intent classification. Everything works on one machine.
When you’re ready to scale, start the daemon on additional machines:
# On each additional node:
pip install mycoswarm
mycoswarm daemon
They auto-discover each other. The orchestrator routes tasks based on real-time capability assessment. GPU nodes handle inference. CPU nodes handle classification and search. No configuration needed.
Add nodes as you find cheap hardware. Every M710Q, old laptop, or Raspberry Pi that joins the network adds capacity. The system adapts automatically.
What’s Next
The cognitive architecture is still growing:
- Procedural memory — storing reusable problem-solving patterns
- Confidence calibration — the system learns to say “I’m not sure” instead of fabricating
- Graph RAG — entity relationships across documents
- Fine-tuned embeddings — training the retrieval model on your specific data
The goal isn’t to compete with GPT-4 or Claude on raw capability. It’s to build a thinking system that runs entirely on your own hardware, respects your privacy, learns from your interactions, and gets better over time — not by training bigger models, but by building better architecture around small ones.
That’s the mycelium philosophy: intelligence isn’t about the size of any single node. It’s about how they connect.
mycoSwarm is open source. Why mycoSwarm was born · mycoSwarm vs Exo, Petals, nanobot This article is part of a series on cognitive architecture for local AI.